
Obwohl die binärkodierte Dezimalzahl in der Regel nicht mehr für Protokolle und Datenspeicherungen verwendet wird, sind ihre Auswirkungen heute spürbar. Alle paar Jahre tauchen, in den Nachrichten, Fälle von gestörten Systemen auf, die plötzlich ein falsches Datum haben oder Geldbeträge falsch lesen/schreiben. Hier ist direkt zu sehen, wo BCD noch immer (vor allem durch die Kompatibilität zu älteren Systemen) verwendet wird. Zum Beispiel Datumszähler im CMOS-RAM, Geburtsdaten, in Transferprotokollen zwischen Bezahlgeräten oder zur Speicherung von Zugangsberechtigungsnummern.
Leider ist immer wieder zu sehen, dass die Konvertierung in native Zahlenformate über Umwege (oder mehrere Konvertierungen) gemacht wird. Das muss natürlich nicht sein.
Beispiel (Quellcode): bcd.cpp
Download (Quellcode): bcd.zip
Beschreibung
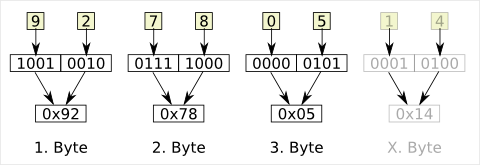 Bei BCD wird jede Dezimalziffer des Wertes für sich gespeichert und zwar binär von Null bis Neun. Da hierfür nur maximal 4 Bit benötigt werden, wird oft die gepackte Variante von BCD eingesetzt.…
Bei BCD wird jede Dezimalziffer des Wertes für sich gespeichert und zwar binär von Null bis Neun. Da hierfür nur maximal 4 Bit benötigt werden, wird oft die gepackte Variante von BCD eingesetzt.…
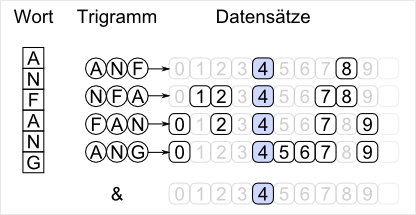
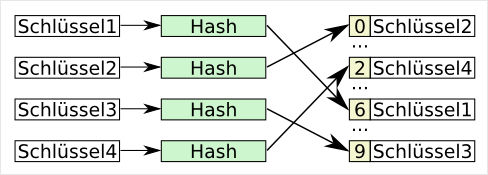 Die Funktion einer Hashtabelle ist sehr einfach. Die Schlüsselwerte werden mit einer Konvertierungsfunktion (Hashfunktion) in einen Wert gewandelt, der direkt als Index für ein Datenfeld benutzt wird. Durch die Verringerung des Schlüssels auf einen kleineren Wertebereich, kann es zu Kollisionen kommen. Das heißt auch, dass die Werte keine eindeutige Referenz für den Schlüssel sind. Somit muss, in der Designphase des Endproduktes, schon drauf geachtet werden, wie mit Kollisionen umgegangen werden soll. Da gibt es gleich einen ganzen Schwung an Möglichkeiten:
Die Funktion einer Hashtabelle ist sehr einfach. Die Schlüsselwerte werden mit einer Konvertierungsfunktion (Hashfunktion) in einen Wert gewandelt, der direkt als Index für ein Datenfeld benutzt wird. Durch die Verringerung des Schlüssels auf einen kleineren Wertebereich, kann es zu Kollisionen kommen. Das heißt auch, dass die Werte keine eindeutige Referenz für den Schlüssel sind. Somit muss, in der Designphase des Endproduktes, schon drauf geachtet werden, wie mit Kollisionen umgegangen werden soll. Da gibt es gleich einen ganzen Schwung an Möglichkeiten: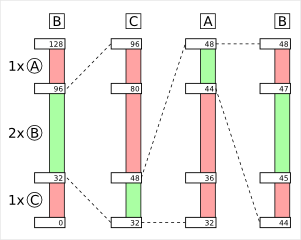 Eine Bereichskodierung ist eine Art der arithmetischen Kodierung, jedoch wird nur mit einem Ausschnitt des Ausgabewertes gerechnet. Die arithmetische Kodierung besitzt einen Ausgabewert und den Bereichswert. Der Ausgabewert ist mit Null initialisiert und der Wert, der später in die A…
Eine Bereichskodierung ist eine Art der arithmetischen Kodierung, jedoch wird nur mit einem Ausschnitt des Ausgabewertes gerechnet. Die arithmetische Kodierung besitzt einen Ausgabewert und den Bereichswert. Der Ausgabewert ist mit Null initialisiert und der Wert, der später in die A…