Hashtabellen finden sehr oft ihren Weg in Anwendungen, bei denen es wichtig ist, bei einer relativ konstanten Laufzeit, Datensätze mit Hilfe eines Schlüssels zu finden.
Beispiel (Quellcode): hashtable.cpp
Download (Quellcode): hashtable.zip
Beschreibung
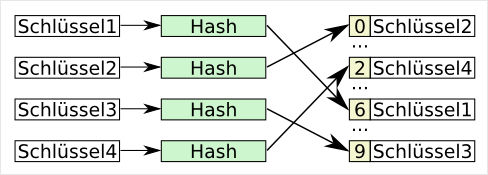 Die Funktion einer Hashtabelle ist sehr einfach. Die Schlüsselwerte werden mit einer Konvertierungsfunktion (Hashfunktion) in einen Wert gewandelt, der direkt als Index für ein Datenfeld benutzt wird. Durch die Verringerung des Schlüssels auf einen kleineren Wertebereich, kann es zu Kollisionen kommen. Das heißt auch, dass die Werte keine eindeutige Referenz für den Schlüssel sind. Somit muss, in der Designphase des Endproduktes, schon drauf geachtet werden, wie mit Kollisionen umgegangen werden soll. Da gibt es gleich einen ganzen Schwung an Möglichkeiten:
Die Funktion einer Hashtabelle ist sehr einfach. Die Schlüsselwerte werden mit einer Konvertierungsfunktion (Hashfunktion) in einen Wert gewandelt, der direkt als Index für ein Datenfeld benutzt wird. Durch die Verringerung des Schlüssels auf einen kleineren Wertebereich, kann es zu Kollisionen kommen. Das heißt auch, dass die Werte keine eindeutige Referenz für den Schlüssel sind. Somit muss, in der Designphase des Endproduktes, schon drauf geachtet werden, wie mit Kollisionen umgegangen werden soll. Da gibt es gleich einen ganzen Schwung an Möglichkeiten:
Ignorieren. Je nach Bedarf der Anwendung, kann der neue Schlüssel wichtiger sein als ein Älterer, z.B. oft bei Kompressionssuchbäumen oder statistischen Daten.
Datenfeld erweitern. Um die Kollisionen geringer werden zu lassen, kann der Wertebereich dynamisch angepasst werden. Dies erfordert bei einer Vergrößerung aber eine Neuerstellung des kompletten Datenfeldes und aller Schlüssel bzw. Hashes.
Doppeltes Hashen. Ist nach dem ersten Hashen eine Kollision vorhanden, kann der Hash zusammen mit dem Schlüssel nocheinmal durch die Konvertierungsfunktion laufen und einen neuen Hash erzeugen. Die Wahrscheinlichkeit ist hoch, dass dort kein Eintrag existiert.
Weitere Klasse behandelt die Daten. Diese Variante stellt, je nach Algorithmus, sicher, dass keine Kollisionen auftreten können. Es werden häufig Listen, weitere Tabellen oder die binäre Suche benutzt.
Sicherheit
Wird eine Hashtabelle mit Daten gefüttert, die direkt vom Benutzer stammen, sollte sichergestellt werden, dass zumindest nach jedem Programmstart, die Hasherzeugung andere Verteilungen liefert. Dies ist wichtig, da sonst von Benutzern hohe Lasten bei Anwendungen durch Kollisionen erzeugt werden können, wenn ihnen der Algorithmus/Werte bekannt sind.
Durch den Beispielcode
Der Beispielcode, enthält zwei Klassen (C++), die beinhaltet die Konvertierungsfunktion und die andere hält das Datenfeld:
der Konstruktor
CHashTable(size_t nSize);38Beim Erzeugen der Klasse wird der maximale Wertebereich angegeben, den die Konvertierungsfunktion maximal Erzeugen kann.
Finden eines Schlüsselswertes
_TYPE& Find(const _KEY& key);46Diese Funktion gibt das Datenfeld des Indexes der Konvertierungsfunktion zurück. Sie kann erweitert werden, um den echten Schlüssel noch einmal zu vergleichen um falsche Ergebnisse ausschließen zu können.
Codeanmerkungen
Der Beispielcode ignoriert Kollisionen (zeigt diese aber an).
Der letzte Aufparameter gibt den suchenden Schlüssel an, der Rest wird als Schlüssel mit einem Pseudoindex hinzugefügt:
for(int n=1; n<argc-1; n++)62So ergibt
./hashtable hash table in aktion indie Ausgabe
Hash table test... 'in' has same hash as key 3