Die Bereichskodierung ist, neben der Huffman-Kodierung, eine mittlerweile häufig anzutreffende Entropiekodierung. Sie ist einfach zu realisieren, kommt der theoretischen Entropie näher, ist aber etwas langsamer. Vor allem in Szenarien mit starken dynamischen oder extremen Symbolwahrscheinlichkeiten macht sich diese Kodierung bezahlt. Im Gegensatz zur Huffman-Kodierung ist die Untergrenze von einem Bit pro Symbol in der Ausgabe aufgehoben, so dass rein vom Betrachter aus, mehr als ein Symbol pro Bit gespeichert werden kann. Dieses Verfahren wird z.B. bei LZMA/7Zip, PPM, PAQ und bei sehr vielen aktuellen Audio-/Videokompressionen eingesetzt.
Beispiel (Quellcode): rangecoder.cpp
Download (Quellcode): rangecoder.zip
Beschreibung
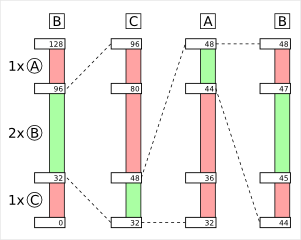 Eine Bereichskodierung ist eine Art der arithmetischen Kodierung, jedoch wird nur mit einem Ausschnitt des Ausgabewertes gerechnet. Die arithmetische Kodierung besitzt einen Ausgabewert und den Bereichswert. Der Ausgabewert ist mit Null initialisiert und der Wert, der später in die Ausgabe geschrieben wird. Der Bereichswert gibt das aktuelle benutzbare Limit an. Zur Symbolkodierung, wird nun der Bereichswert durch die Summe aller Symbolhäufigkeiten geteilt. Das ergibt einen Basiswert. Der Basiswert wird nun mit der Summe alle Symbolhäufigkeiten unter dem aktuellen Symbol multipliziert und zum Ausgabewert addiert. Für den neuen Bereichswert wird der Basiswert mit der Symbolhäufigkeit des aktuellen Symbols multipliziert. (Links im Bild, ein Beispiel mit drei Symbolen und unterschiedlichen Häufigkeiten.)
Eine Bereichskodierung ist eine Art der arithmetischen Kodierung, jedoch wird nur mit einem Ausschnitt des Ausgabewertes gerechnet. Die arithmetische Kodierung besitzt einen Ausgabewert und den Bereichswert. Der Ausgabewert ist mit Null initialisiert und der Wert, der später in die Ausgabe geschrieben wird. Der Bereichswert gibt das aktuelle benutzbare Limit an. Zur Symbolkodierung, wird nun der Bereichswert durch die Summe aller Symbolhäufigkeiten geteilt. Das ergibt einen Basiswert. Der Basiswert wird nun mit der Summe alle Symbolhäufigkeiten unter dem aktuellen Symbol multipliziert und zum Ausgabewert addiert. Für den neuen Bereichswert wird der Basiswert mit der Symbolhäufigkeit des aktuellen Symbols multipliziert. (Links im Bild, ein Beispiel mit drei Symbolen und unterschiedlichen Häufigkeiten.)
Für die Dekodierung wird nahezu gleich (nur umgekehrt) vorgegangen, jedoch wird nach dem dividieren des Eingangswertes durch den Basiswert geschaut, zur welcher Summe von Symbolhäufigkeiten das Ergebnis passt und mit der Häufigkeit des gefundenen Symbols fortgefahren.
Das Prinzip der arithmetischen Kodierung ist bei der Bereichskodierung identisch, jedoch ist der Wertebereich viel kleiner, da eine arithmetische Kodierung theoretisch eine quasi unendliche Genauigkeit haben muss. Meist wird hier, sowohl für den Ausgabewert und den Bereichswert, ein 32 Bit oder 64 Bit Register genommen.
Das ergibt gleich einige Probleme, jedoch auch Lösungen:
Zum Einen wird der Bereichswert nach ein paar Durchläufen viel zu klein um damit noch aussagekräftige Werte zu erhalten. Daher wird beim Unterlauf des Bereichswertes der bisher bekannte obere Teil des Ausgabewertes in die Ausgabe gepackt. Danach werden beide Werte "normalisiert", also wieder erweitert auf einen möglichst großen Wert.
Durch die Normalisierung kann es passieren, dass ein Überlauf bei der nächsten Addition des Symbolwertes entstehen kann. Dieser Überlauf muss auf die bisherige Ausgabe angerechnet werden. Also muss ein Teil der Ausgabe gepuffert oder eine andere Vorkehrung getroffen werden, damit der Ausgabewert nicht verfälscht wird bzw. richtig ist.
Durch den eingeschränkten Wertebereich, kann der Bereichswerte/Ausgabewert nicht in seiner maximalen Auflösung wirken. Somit wird meist nicht die beste Entropie erreicht. Je größer der Wertebereich und je häufiger normalisiert werden kann, desto näher rückt das Limit. Da die Ausgabe meist in Byteform existiert, macht sich das erst auf größeren Datensätzen bemerkbar. So kann hier, zwischen Genauigkeit und Zeitaufwand, entschieden werden.
Werden keine adaptiven Codes verwendet, so gibt es die gleiche Einschränkung wie bei der Huffman-Kodierung: Die Symbolhäufigkeiten müssen auch in die Ausgabe. Dies ist wesentlich komplizierter, denn hier müssen genaue Wahrscheinlichkeiten benutzt werden, sonst verliert die Bereichskodierung ihre Vorzüge. Das ist ein Grund weshalb eigentlich alle Implementationen adaptive oder statische Codes haben.
Durch den Beispielcode
Der Beispielcode, enthält zwei Klassen (C++), die eine zum Aufnehmen der Symbolhäufigkeiten und eine zum Kodieren:
der Konstruktor
CRangeCoder(int nRangeBits=31);16Beim Erzeugen der Klasse wird der maximale Wertebereich angegeben. Bei größeren Wertebereichen müssen ggf. Variablen in der Klasse angepasst werden, damit diese den Wertebereich aufnehmen können.
Kodierung eines Symbols
void AddCode(uint32_t nCode, uint32_t nMax);22Diese Funktion fügt den Code der Ausgabe hinzu, "nMax" gibt die Summe aller Symbolhäufigkeiten und "nCode" die Summe aller Häufigkeiten unter dem Symbol an.
Ausgabe und neuer Bereichswert
void CommitRangeWrite(uint32_t nRange, uint32_t nMax);38Über diesen Aufruf werden alle überschüssigen Werte weggeschrieben und der Bereichswert mit Hilfe von "nRange" neu gesetzt und ggf. normalisiert. "nRange" ist hier die Symbolhäufigkeit des aktuellen kodierten Symbols.
Ausgabe nicht geschriebener Werte
void Flush();83Wenn die Eingabe leer ist, können über diese Funktion die restlichen Werte im Puffer weggeschrieben werden.
Codeanmerkungen
Der Beispielcode hat keine vollständige Dekodiereinheit.
Der Beispielcode gibt einzelne Bits aus.
Die Erzeugung der Häufigkeitentabelle wird durch Build() in CHistogram erledigt.
Der erste Aufrufparameter des Programms bildet eine Eingabezeichenkette die mit der Bereichskodierung umgeschrieben wird:
std::vector<int> codes; for(size_t n=0; n<strlen(argv[1]); n++) codes.push_back(argv[1][n]);215 216 217So ergibt
./rangecoder "dies_ist_ein_test"die Ausgabe
Range coder test... Tables: 95 (_). 3 100 (d). 1 101 (e). 3 105 (i). 3 110 (n). 1 115 (s). 3 116 (t). 3 Encoded: 0011 0100 0101 0000 0101 1110 1101 0111 1100 0011 0000 11 Bits in: 8x17=136 Bits out: 46 = 2.706 bits/code entropy Theoretical lower bound for entropy is: 45.712 bits = 2.689 bits/code