Die Huffman-Kodierung stellt neben der arithmetischen Kodierung bzw. der Bereichskodierung eine der häufigsten Formen der Entropiekodierung dar. Es wird und wurde vor allem, wegen der hohen Geschwindigkeit in älteren Kompressionsverfahren eingesetzt, von ZIP/Deflate über RAR bis hin zu JPEG. Allerdings gibt es auch einen kleinen Nachteil: Die Kodierung erreicht nicht immer die theoretische Entropie, da sie nur auf Bitbasis arbeitet.
Beispiel (Quellcode): huffman.cpp
Download (Quellcode): huffman.zip
Beschreibung
Diese Art der Kodierung, errechnet mit Hilfe der Symbolauftrittswahrscheinlichkeiten (oder auch Häufigkeiten), einen möglichst kurzen und eindeutigen Code. Kommt ein Symbol häufiger vor, wird es durch einen kürzeren binären Code ausgedrückt. Werden nicht alle Symbole des Alphabets benötigt, fließen diese nicht weiter in die Bearbeitung ein. Grundsätzlich kann unterschieden werden zwischen statischer, dynamischer und adaptiver Huffman-Kodierung. Die statische hat festgelegte Symbolhäufigkeiten, die dynamische ermittelt diese selbst über einige Symbole oder der ganzen Nachricht. Bei der adaptiven Kodierung wird nach jedem Symbol die Codetabelle angepasst.
Zu Beginn wird die Häufigkeitsverteilung aufgenommen (wie beim Countingsort). Danach werden immer die beiden kleinsten Häufigkeiten, in einem Baum vereint, wobei dieser Eintrag dann wieder, im nächsten Durchlauf, zur Verfügung steht. Diese Operation wird solange ausgeführt, bis nur noch ein Eintrag übrig ist. Ab hier ist es theoretisch schon möglich, die Codes über den erzeugten Baum zu ermitteln (z.B. linker Eintrag für 0 und rechter für 1). Für die adaptive Kodierung genügt dies, da sie keine Tabellen speichern muss.
Anders die dynamische Kodierung. Bei der reicht es nicht, die reinen Codes abzulegen, da der Dekoder keinen Anhaltspunkt über die Häufigkeiten der Symbole im nachfolgenden Block hat. Die Häufigkeitswerte zu speichern, würde die Ausgabe wieder unnötig groß machen. Daher wird für jeden Code nur die Anzahl der Bits abgelegt (häufig noch einmal mit RLE- und Huffman-Kodierung). Anhand der Bits für jeden Code kann dessen Codewort abgeleitet werden. Dies muss nicht zwangsweise die binäre Folge aus dem Baum sein.
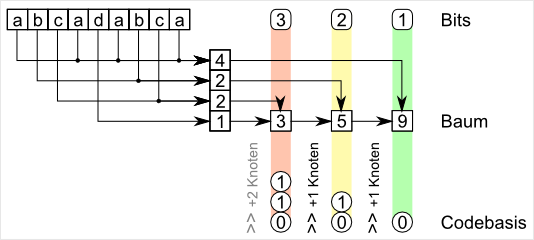
Die Basis der Codes kann aus dem vorhergehenden Codebasis und der Anzahl der Symbole des Bits ermittelt werden. Dies wird aber genauer im Beispielcode verdeutlicht.
Die Dekodierung erfolgt genau umgekehrt, wobei natürlich zum Vergleich der Codewörter Tabellen angelegt werden können, so dass nur ein Zugriff nötig ist, das Symbol zu erkennen.
Durch den Beispielcode
Der Beispielcode, enthält eine Klasse (C++), die einen einzelnen Huffmanbaum und Codewörter aufnehmen kann:
der Konstruktor
CHuffman(size_t nSymbols);27Beim Erzeugen der Klasse wird die maximale Anzahl der Symbole angegeben.
Baumerzeugung und Codewörter
void BuildTree(const std::vector<int>& codes);30Diese Funktion erzeugt den Baum und die Codewörter.
Übersetzen der Symbole in Codewörter
void Encode(const std::vector<int>& codes);107Da es nur ein Beispiel ist, werden die Codewörter als Ausgabe angegeben, sowie die erreichte und theoretische Entropie angezeigt.
Codeanmerkungen
Der Beispielcode hat keine Dekodiereinheit.
Die Erzeugung des Baums in BuildTree() ist das einfachste Beispiel, keinesfalls die schnellste Implementierung.
Mit dem ersten Aufrufparameter des Programms wird die Eingabezeichenkette mit der Huffman-Kodierung umgeschrieben:
std::vector<int> codes; for(size_t n=0; n<strlen(argv[1]); n++) codes.push_back(argv[1][n]);194 195 196So ergibt
./huffman "abcadabca"die Ausgabe
Huffman test... Tables: 97 (a). 4 codes / 1 bits 0 98 (b). 2 codes / 2 bits 10 99 (c). 2 codes / 3 bits 110 100 (d). 1 codes / 3 bits 111 Encoded: 0 10 110 0 111 0 10 110 0 Bits in: 8x9=72 Bits out: 17 = 1.889 bits/code entropy Theoretical lower bound for entropy is: 16.529 bits = 1.837 bits/code