Ein Filter für bestimmte Datenmuster ist immer dann brauchbar, wenn Datensätze eingegrenzt bzw. ausgeschlossen werden sollen. Es wird hier anhand eines Filters zur Eingrenzung von Zeichenkettensuchoperationen, mit einem Beispiel, beschrieben. Natürlich lässt sich dieses Verfahren auf beliebige Daten anwenden und ist eine effektive Hilfe die nötigen Suchoperationen stark zu verringern und somit die Laufzeit des Codes zu verbessern.
Beispiel (Quellcode): patternfilter.cpp
Download (Quellcode): patternfilter.zip
Beschreibung
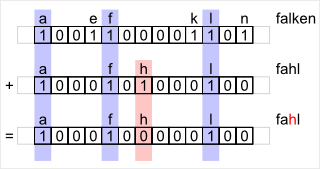 Mit Hilfe einer Funktion zur Mustererzeugung, wird jedes Element des Objektes in einem Datenfeld (entspricht einem Alphabet) mit seinem Wert als vorhanden markiert. Besteht ein Element aus mehreren Teilen, kann auch der Hashwert verwendet werden. Dies ist für das zu durchsuchende Muster sowie für das gesuchte Muster gleich. Sind die gleichen Markierungen, für beide Muster, im Datenfeld vorhanden, sind gleiche Elemente in den Objekten.
Mit Hilfe einer Funktion zur Mustererzeugung, wird jedes Element des Objektes in einem Datenfeld (entspricht einem Alphabet) mit seinem Wert als vorhanden markiert. Besteht ein Element aus mehreren Teilen, kann auch der Hashwert verwendet werden. Dies ist für das zu durchsuchende Muster sowie für das gesuchte Muster gleich. Sind die gleichen Markierungen, für beide Muster, im Datenfeld vorhanden, sind gleiche Elemente in den Objekten.
Da aber die Position der Elemente nicht, ggf. Hashwerte und ein begrenztes Datenfeld verwendet wird, kann es vorkommen, dass es auch Positivmeldungen geben kann, obwohl es kein übereinstimmendes Element gab. Umgekehrt kann aber gesagt werden, dass nicht gefundene Elemente wirklich nicht vorkommen konnte.
Daher eignet sich der Filter gut, um große Vergleiche gar nicht erst unnötig starten zu müssen. Im Gegensatz zum Hashen von Objekten, werden keine kompletten Übereinstimmungen benötigt, sondern nur Teilübereinstimmungen.
Es muss vorher abgewogen und/oder ausprobiert werden, ob sich die Implementierung lohnt. Das Datenfeld sollte letztendlich effizienter zu vergleichen sein als das eigentliche Objekt. Im Idealfall ist das Datenfeld ein nativer Datentyp, den der Prozessor am besten mit wenigen Operationen bearbeiten und vergleichen kann.
Mustererzeugung im Beispiel
Im Beispiel werden alle Kombinationen von drei folgenden Zeichen der Eingangszeichenkette auf das Datenfeld gelegt. Die Werte werden noch ein bisschen geschoben/multipliziert, damit Dreher in den Kombinationen andere Werte liefern. Zusätzlich wird der errechnete Wert mit einem Modulo runter geschnitten, um die Datenfeldgrenzen nicht zu überschreiten. In diesem Fall ein 64-Bit Integer.
for(size_t n=0; n<sTextPattern.length()-2; n++)
nPattern |= 1LL<<(((int)sTextPattern[n]+(int)sTextPattern[n+1]*7-(int)sTextPattern[n+2]*13)&63);17
18
Mustervergleich im Beispiel
Im Muster wird gegen die gesetzten Bits in der Suche verglichen. Sind alle Bits vorhanden, kann das gesuchte Wort enthalten sein. Hierfür bietet sich die UND-Operation an.
return (nPattern&nSearch)==nSearch?true:false;25
Musterverknüpfung im Beispiel
Die Datenfelder aller Zeichenketten oder Teilmengen davon, können verknüpft werden. Danach ist es möglich, den Filter über alle Zeichenketten gleichzeitig anzuwenden. Im realer Umgebung können so, zum Beispiel mehrere Objekte simultan gefiltert und die nötigen Operationen zur Suche weiter gesenkt werden.
nGlobalPattern |= strings[n].GetPattern();72
Codeanmerkungen
Die Ausrufparameter des Programms, bis auf das letzte, werden als zu suchende Objekte benutzt und deren Muster ausgegeben:
for(int n=0; n<argc-2; n++) ... strings[n] = argv[n+1];69 70 71Der letzte Aufrufparameter wird als Muster ausgegeben gesucht.
CPatternString search(argv[argc-1]);76So ergibt
./patternfilter "test ist schoen" "test ist gut" "ist gut oder" "ist schoen oder" "gut nicht" "schoen nicht" schoendie Ausgabe
Pattern filter test... 0: e000054111010000 1: 8040054102000001 2: 8042040022200403 3: e0000c0131210480 4: 4040000000c02042 5: 0100000111c120c0 S: 0000000111010000 found in global search pattern string 0 matched filter string 3 matched filter string 5 matched filter 3 possible matches for given string