

Bei vielen Kompressionsarten kommt, als Filter, die Lauflängenkodierung zum Einsatz. Sie ist sehr einfach, sehr schnell aber auch sehr spezialisiert, da bei ihr gleiche aufeinander folgende Symbole zusammengefasst werden. Diese Kodierung ist anzutreffen bei vielen Grafikformaten (inklusive JPEG).
Beispiel (Quellcode): rle.cpp
Download (Quellcode): rle.zip
Beschreibung
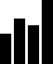
 Wie schon erwähnt, werden gleiche aufeinander folgende Symbole zusammengefasst. Dies geschieht oft durch einen Marker, ein Spezialsymbol oder durch eine andere Art von Metadaten innerhalb des Ausgabedatenstroms. Bei Kodierungsverfahren mit Codewörtern, lassen sich extra Codes verwenden. Die Länge der Symbolwiederholungen, die benötigt wird, um eine Datenkompression zu erreichen hängt vom Kodierungsverfahren ab. Bei einfachsten Implementationen, lohnt sich der Aufwand oft erst, wenn mindestens vier oder fünf gleiche aufeinander folgende Symbole möglich sind.
Wie schon erwähnt, werden gleiche aufeinander folgende Symbole zusammengefasst. Dies geschieht oft durch einen Marker, ein Spezialsymbol oder durch eine andere Art von Metadaten innerhalb des Ausgabedatenstroms. Bei Kodierungsverfahren mit Codewörtern, lassen sich extra Codes verwenden. Die Länge der Symbolwiederholungen, die benötigt wird, um eine Datenkompression zu erreichen hängt vom Kodierungsverfahren ab. Bei einfachsten Implementationen, lohnt sich der Aufwand oft erst, wenn mindestens vier oder fünf gleiche aufeinander folgende Symbole möglich sind.
Wie bei eigentlich allen Kompressionsverfahren, kann auch bei RLE unter Umständen ü…
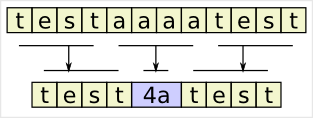
 Bei BCD wird jede Dezimalziffer des Wertes für sich gespeichert und zwar binär von Null bis Neun. Da hierfür nur maximal 4 Bit benötigt werden, wird oft die gepackte Variante von BCD eingesetzt.…
Bei BCD wird jede Dezimalziffer des Wertes für sich gespeichert und zwar binär von Null bis Neun. Da hierfür nur maximal 4 Bit benötigt werden, wird oft die gepackte Variante von BCD eingesetzt.…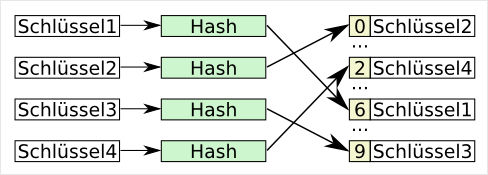 Die Funktion einer Hashtabelle ist sehr einfach. Die Schlüsselwerte werden mit einer Konvertierungsfunktion (Hashfunktion) in einen Wert gewandelt, der direkt als Index für ein Datenfeld benutzt wird. Durch die Verringerung des Schlüssels auf einen kleineren Wertebereich, kann es zu Kollisionen kommen. Das heißt auch, dass die Werte keine eindeutige Referenz für den Schlüssel sind. Somit muss, in der Designphase des Endproduktes, schon drauf geachtet werden, wie mit Kollisionen umgegangen werden soll. Da gibt es gleich einen ganzen Schwung an Möglichkeiten:
Die Funktion einer Hashtabelle ist sehr einfach. Die Schlüsselwerte werden mit einer Konvertierungsfunktion (Hashfunktion) in einen Wert gewandelt, der direkt als Index für ein Datenfeld benutzt wird. Durch die Verringerung des Schlüssels auf einen kleineren Wertebereich, kann es zu Kollisionen kommen. Das heißt auch, dass die Werte keine eindeutige Referenz für den Schlüssel sind. Somit muss, in der Designphase des Endproduktes, schon drauf geachtet werden, wie mit Kollisionen umgegangen werden soll. Da gibt es gleich einen ganzen Schwung an Möglichkeiten: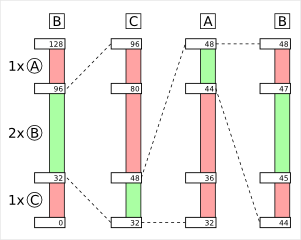 Eine Bereichskodierung ist eine Art der arithmetischen Kodierung, jedoch wird nur mit einem Ausschnitt des Ausgabewertes gerechnet. Die arithmetische Kodierung besitzt einen Ausgabewert und den Bereichswert. Der Ausgabewert ist mit Null initialisiert und der Wert, der später in die A…
Eine Bereichskodierung ist eine Art der arithmetischen Kodierung, jedoch wird nur mit einem Ausschnitt des Ausgabewertes gerechnet. Die arithmetische Kodierung besitzt einen Ausgabewert und den Bereichswert. Der Ausgabewert ist mit Null initialisiert und der Wert, der später in die A…