

Ein recht interessanter, nicht direkt offensichtlicher Fehler, kam mir vor einiger Zeit unter die Finger. Hierzu ein Stück Code:
class CMyVariant
{
public:
CMyVariant();
virtual ~CMyVariant();
// Getter & Setter
protected:
union
{
int64_t nTime;
float fValue;
};
};
int main()
{
CMyVariant v1;
...
// Variant v1 setzt nTime
...
CMyVariant v2 = v1;
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
Auswirkungen
Die Klasse soll einen Variant-Datentypen darstellen, der zum Transport von Werten über Netzwerke und innerhalb von Anwendung benutzt werden kann. Der Wert nTime hält eine Zeit in Millisekunden, dieser sollte die aktuelle Uhrzeit tragen, war jedoch ca. alle 24 Tage um 70 Minuten versetzt. Wie dass?
Analyse
Da es eine Regelmäßigkeit gibt, die scheinbar mit der Zeit zusammenhängt, lassen sich die Werte gut zurückrechnen (in Millisekunden):
- 70 Minuten = 4200000 Millisekunden = 0x00401640
- 24 Tage = 2073600000 Millisekunden…
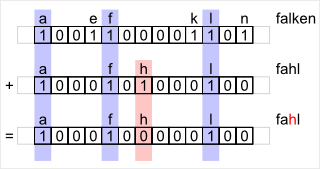 Mit Hilfe einer Funktion zur Mustererzeugung, wird jedes Element des Objektes in einem Datenfeld (entspricht einem Alphabet) mit seinem Wert als vorhanden markiert. Besteht ein Element aus mehreren Teilen, kann auch der Hashwert verwendet werden. Dies ist für das zu durchsuchende Muster sowie für das gesuchte Muster gleich. Sind die gleichen Markierungen, für beide Muster, im Datenfeld vorhanden, sind gleiche Elemente in den Objekten.
Mit Hilfe einer Funktion zur Mustererzeugung, wird jedes Element des Objektes in einem Datenfeld (entspricht einem Alphabet) mit seinem Wert als vorhanden markiert. Besteht ein Element aus mehreren Teilen, kann auch der Hashwert verwendet werden. Dies ist für das zu durchsuchende Muster sowie für das gesuchte Muster gleich. Sind die gleichen Markierungen, für beide Muster, im Datenfeld vorhanden, sind gleiche Elemente in den Objekten.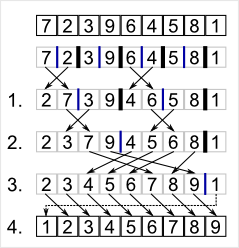 Bei der rekursiven Variante ist es möglich, das Eingangsfeld immer zu halbieren (linke und rechte Hälfte), bis nur zwei oder weniger Elemente zu Verfügung stehen. Die maximale Rekursionsebene liegt bei log2 der Elementgesamtanzahl. Bei Beispielhaften 65536 Elementen also nur 16 Ebenen.
Bei der rekursiven Variante ist es möglich, das Eingangsfeld immer zu halbieren (linke und rechte Hälfte), bis nur zwei oder weniger Elemente zu Verfügung stehen. Die maximale Rekursionsebene liegt bei log2 der Elementgesamtanzahl. Bei Beispielhaften 65536 Elementen also nur 16 Ebenen.